Chapter 11: Security Operations, Monitoring, and Threat Hunting
Learning Outcomes:
- Analyze data from SIEM solutions to identify trends, prioritize alerts, and reduce audit logs.
- Establish behavior baselines and analytics for networks, systems, users, and applications (UBA/UEBA).
- Incorporate diverse data sources into monitoring activities.
- Formulate alerting rules and metrics to minimize false positives and measure security effectiveness.
- Apply threat-hunting concepts using hypothesis-based searches, honeypots, and internal reconnaissance.
- Evaluate external threat intelligence sources, including OSINT, dark web monitoring, and ISACs.
- Implement threat intelligence platforms (TIPs) and indicator of compromise (IoC) sharing standards (STIX/TAXII).
- Develop rule-based detection logic using languages such as Sigma, YARA, and Snort.
Introduction
The previous chapters built defenses. This chapter is about watching them — turning the volumes of telemetry that every modern environment produces into actionable signal, baselining what "normal" looks like so anomalies stand out, hunting for adversaries who managed to slip past the preventative controls, and learning from the global threat-intelligence community so each organization is not detecting everything from scratch.
The hard problem in security operations is no longer collecting data — every endpoint, firewall, identity provider, cloud service, and application produces logs by default. The hard problem is making sense of it: which records are worth an analyst's attention, which alerts are worth waking someone up over, and which gaps in coverage are the ones an adversary will exploit. A mature SOC measures itself not by the number of events ingested but by mean time to detect (MTTD), mean time to respond (MTTR), and how many real incidents it catches versus how many escape into the post-incident review of "why did we have telemetry but no alert?"
We start with the SIEM pipeline — collection, normalization, storage, correlation — because everything in this chapter depends on that data plane working. We then move to behavioral baselines (UEBA) that let anomalies surface without explicit rules, proactive threat hunting that goes looking for adversaries on a hypothesis rather than waiting for alerts, and finally the external threat intelligence ecosystem (OSINT, ISACs, STIX/TAXII, YARA/Sigma) that lets a defender benefit from what the rest of the industry has already learned.
How Do We Make Sense of Security Data?
A modern enterprise produces tens of billions of log records a day across endpoints, network devices, identity systems, cloud services, and applications. None of that data is useful in raw form. The discipline of turning it into signal is Security Information and Event Management (SIEM) — historically a category of product (Splunk, IBM QRadar, Microsoft Sentinel, Elastic Security, Chronicle, Sumo Logic), increasingly a pattern that combines a data lake, a detection engine, and a workflow layer regardless of vendor.
SIEM Log Aggregation and Correlation
A SIEM pipeline has five stages, each with its own failure modes.
- Collection. Agents and forwarders pull or receive logs from sources: syslog from network devices, the Windows Event Log via WEF, EDR telemetry via vendor APIs, cloud audit logs (AWS CloudTrail, Azure Activity Log, GCP Cloud Audit Logs) via streaming, application logs via Fluent Bit / Vector / Filebeat, identity provider logs via API.
- Normalization and enrichment. Raw records are parsed into a consistent schema — increasingly the Elastic Common Schema (ECS) or the Open Cybersecurity Schema Framework (OCSF) — and enriched with context the raw record lacks: GeoIP, asset criticality, user role, threat-intelligence overlap.
- Storage and indexing. Normalized data is written into a searchable store, typically with hot / warm / cold retention tiers — fast SSD for recent days, slower object storage for months-to-years, archive for compliance retention.
- Correlation and detection. Rules — written in vendor-specific languages or the cross-platform Sigma standard — combine multiple events into higher-level alerts. UEBA models flag statistical anomalies the rules would never have anticipated.
- Alerting, dashboards, and response. Alerts route to analysts; dashboards summarize trends; SOAR playbooks (Chapter 12) automate response on the most common patterns.
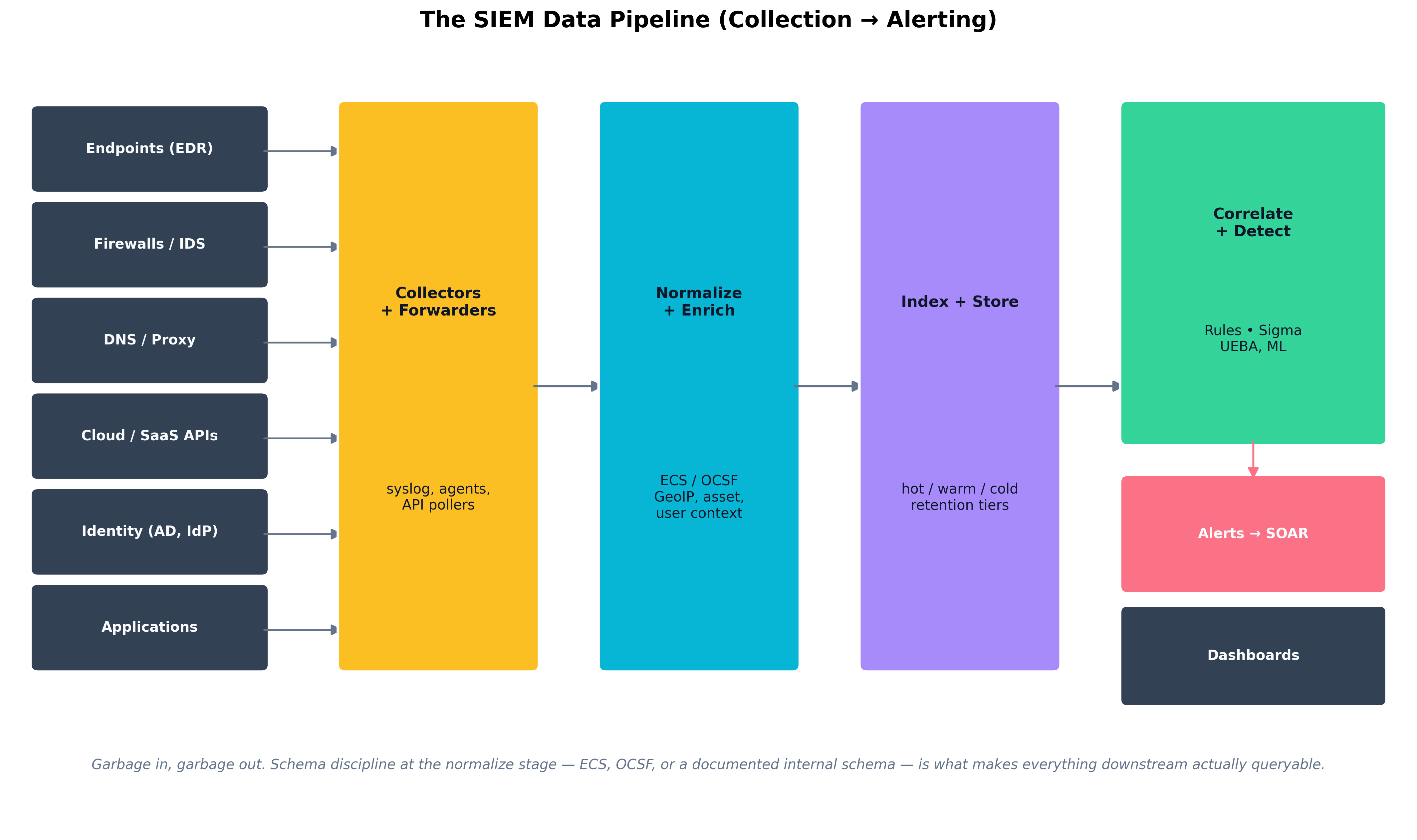 Figure 11.1: The SIEM pipeline flows from heterogeneous sources through collectors and forwarders into a normalization-and-enrichment stage, then into indexed storage, correlation and detection, and finally to alerts, dashboards, and SOAR workflows. Schema discipline at the normalize stage is what makes everything downstream queryable across data sources.
Figure 11.1: The SIEM pipeline flows from heterogeneous sources through collectors and forwarders into a normalization-and-enrichment stage, then into indexed storage, correlation and detection, and finally to alerts, dashboards, and SOAR workflows. Schema discipline at the normalize stage is what makes everything downstream queryable across data sources.
Prioritizing Alerts and Reducing Noise
Most SOCs do not fail because they detect too little — they fail because they detect too much. An analyst who receives 400 alerts a day cannot triage them with care; some will be ignored, and the ignored ones will eventually include real attacks. Five disciplines reduce this:
- Tune at the source. Suppress noisy events at the agent or forwarder rather than ingesting and then filtering them — every byte that does not need to be stored is cost saved and noise removed.
- Stage alerts by severity, asset criticality, and user privilege. An alert on a domain controller from a domain admin's account is not the same priority as the same alert on a workstation.
- Use detection-as-code. Detections live in a Git repository, get code review, are versioned, and are retired when they outlive their usefulness — the same engineering rigor as application code.
- Maintain a known-noise allowlist. Vulnerability scanners, internal penetration tests, and developer experiments should be enumerable so they do not trip detections.
- Measure false-positive rate (FPR) per detection. A rule with a 95% FPR is doing more harm than good and should be tuned or retired.
Key Point Coverage gaps and noise are two sides of the same problem. You cannot tell an analyst to "look harder" past the noise — you have to engineer the noise down before they can see signal. The MITRE ATT&CK framework is increasingly used to measure coverage gap-by-gap: which techniques does the org have detections for, at what fidelity, and where are the holes?
Diverse Data Sources
Every additional data source the SIEM correlates against multiplies its detective power, but only if the data is parsed correctly and the right relationships are modeled. The high-leverage sources for any modern SOC:
- Endpoint (EDR). Process creation, file write, registry edit, network connection, syscall pattern.
- DNS. Query logs from the recursive resolver — extraordinarily high signal-to-noise for malware C2.
- Authentication. Active Directory and identity-provider logs (Entra ID, Okta) — the substrate of every credential-based attack.
- Cloud control plane. CloudTrail / Activity Log / Audit Logs — captures every API call.
- DLP. Egress and copy-paste events.
- Vulnerability scan results. Posture context that informs alert prioritization.
- Email gateway. Delivery, signature failure, sandbox detonation results.
- Third-party security telemetry. CASB, CSPM, attack-surface management feeds.
| Property | STIX (Structured Threat Information eXpression) | TAXII (Trusted Automated eXchange of Indicator Information) |
|---|---|---|
| What it is | A language / data model for describing threat intelligence | A transport protocol for exchanging threat intelligence |
| Layer | Information layer | Transport layer |
| Current version | STIX 2.1 (2021) | TAXII 2.1 (2021) |
| Format | JSON objects (indicators, malware, campaigns, threat actors, TTPs, sightings) | HTTPS REST API with collections and channels |
| Typical use | Encoding IoCs, ATT&CK mappings, campaign descriptions | Pulling / pushing STIX bundles between TIPs, ISACs, and vendors |
| Analogy | Like the language of an email | Like the SMTP protocol that carries it |
| Table 11.1: STIX and TAXII are complementary, not alternatives. STIX defines what threat intelligence looks like as data; TAXII defines how that data moves between systems. A modern Threat Intelligence Platform consumes TAXII feeds and stores STIX objects. |
Dashboards, Reporting, and Security Metrics
Dashboards exist for two audiences with very different needs:
- Operational dashboards (for analysts) show real-time alert queues, dwell on open cases, current investigation status, and the day-over-day trend on top noisy detections.
- Executive dashboards (for leadership) show longer-horizon metrics: MTTD, MTTR, alert volume by severity, coverage against MITRE ATT&CK, incident counts by type, and trend lines on the security KPIs the program is committed to. Vanity metrics like "number of events processed" should be ruthlessly resisted; they grow with the data, not the defenders' effectiveness.
Example
A high-fidelity multi-source detection
The single highest-value detection in many SOCs is not exotic — it is the cross-source correlation of three boring events on the same user within minutes:
- An authentication from an unfamiliar country / ASN to an identity provider (Okta, Entra ID).
- A mailbox rule created shortly after that auth that forwards or auto-deletes mail (a hallmark of business email compromise).
- An OAuth grant to an unfamiliar third-party application requesting mail-read permissions.
Individually, each event has a substantial false-positive rate — travelers exist, users do legitimately create rules, OAuth apps are not all malicious. Together within a fifteen-minute window on the same user account, they are nearly diagnostic of credential compromise. The detection requires authentication logs, mailbox audit logs, and OAuth grant logs all in the same SIEM with a shared user identifier. None of that is exotic. Most organizations simply have not connected the data.
How Do We Baseline Normal Behavior?
Rules are the most explicit way to detect — "if X then alert" — but rules can only catch things you anticipated. Behavioral analytics flip the problem around: learn what is normal for each user, host, network segment, and application, then alert on statistically significant deviations.
User and Entity Behavior Analytics (UEBA)
User and Entity Behavior Analytics (UEBA) systems build per-entity baselines from historical telemetry and detect anomalies against those baselines. Modern UEBA capabilities include:
- Per-user feature vectors. Typical login hours, geographies, devices, applications, peer group membership, data-access patterns.
- Per-host baselines. Normal process trees, child-process relationships, outbound destinations, scheduled-task inventories.
- Peer-group analysis. A finance analyst accessing engineering source control is suspicious not because access is impossible — it might be authorized — but because peers in finance do not do it.
- Risk scoring. Anomalies compose into a numerical risk score per entity. Users above a threshold surface for analyst review, with the constituent anomalies linked.
- Adaptive thresholds. Baselines update as the environment evolves; static thresholds rot quickly.
UEBA shines against three classes of threat that static rules struggle with: compromised credentials (the attacker has valid login but does not behave like the user), insider threats (the user has legitimate access but is using it abnormally), and lateral movement post-compromise (an attacker on a foothold host is reaching systems the host never reached before).
Identifying Anomalies in Systems and Apps
UEBA is not limited to users. Entity behavior generalizes the idea to any first-class object: workstations, servers, service accounts, applications, IoT devices. The most fruitful anomalies in practice are usually the unglamorous ones:
- A service account suddenly performing interactive logons.
- A backup server initiating outbound HTTPS to an unfamiliar destination.
- A workstation generating DNS queries at 4× its normal rate at 2 a.m.
- A database that has historically responded only to three application accounts beginning to receive queries from a new source.
- An EDR agent that has stopped reporting from a host that is still pinging on the network.
Each of those anomalies is hard to express as a static rule and almost impossible to anticipate by name — but easy to detect once you have a baseline.
Case Study
Hamlet, the Insider, and the Off-Hours Database Queries
Hamlet, threat hunter at Denmark Cyber Defense, is reviewing the weekly UEBA risk-score report on a Wednesday morning when one entity stands out: a developer account belonging to a contractor who has been with the firm for nine months. The score is 78 out of 100, up from a baseline near 5, accumulated over the past eleven days.
Hamlet clicks through. The constituent anomalies tell a story when read together:
- Eleven nights running, the account has logged into a database read-replica at roughly 11:30 p.m. — outside the user's historical 9 a.m. – 6 p.m. login pattern. The replica is one the user has access to but has never used in nine months on the job.
- The queries run against the replica are unusually large —
SELECT *across the customer table, withLIMITvalues incrementing each night (1000, then 5000, then 25000) as if the user were testing what size of result would not trigger alarms.- The result sets are written to a local CSV under the user's home directory on the developer workstation, and the workstation's outbound HTTPS volume in the half-hour after each query is roughly 4× the user's baseline — but split across multiple destinations including a personal cloud storage domain.
- The user has not opened the company chat app or email between 11 p.m. and 6 a.m. on any of those eleven nights — they are awake and active only on the database and the file uploads.
No individual event would have tripped a static rule. The database access is technically authorized. The hours are unusual but not impossible. The data volumes are within ordinary day-to-day variance for a developer pulling test data. Even the personal cloud storage upload, in isolation, would have produced a low-priority DLP alert that the queue routinely dismissed.
Together, the pattern is unmistakable. Hamlet escalates to the incident response team, who pull the workstation's EDR timeline and confirm a script that automates the SELECTs and uploads. HR and legal are looped in; the contractor's access is suspended pending investigation. The full extracted volume — about 380,000 customer records over the eleven-day window — is recovered from the personal cloud storage provider through a preservation-and-disclosure process, and not (so far as can be determined) exfiltrated further.
The post-incident review produces two changes. The UEBA risk-score threshold for off-hours database access is lowered for accounts that have never historically accessed that database, even when access is technically permitted. And a separate DLP rule is added for the specific personal-cloud-storage domain involved, since the company already used a different provider sanctioned for business use.
The case is the textbook example of why behavioral analytics matter: an attacker — internal or external — who has legitimate access is invisible to access-control alone. Only deviation from baseline reveals them.
How Do We Proactively Hunt for Threats?
Detective controls catch attackers when they trip an alarm. Threat hunting assumes the alarms have already failed — that some adversary is already inside the environment, evading detection — and goes looking for them based on a hypothesis about how they would behave. Hunting is what separates a reactive SOC from a proactive one.
Internal Reconnaissance and Honeypots
A threat hunt starts with a hypothesis ("an adversary using technique X would leave artifact Y") and ends with one of three outcomes: an incident, a new detection that operationalizes what was learned, or a documented coverage confirmation. The hunt itself draws on the same telemetry the SIEM already ingests, but interrogated by a human asking questions a rule could not.
Honeypots and honeynets are deception infrastructure that produce extraordinarily high-fidelity signal precisely because there is no legitimate reason for anyone to interact with them. A honeypot is a single decoy system; a honeynet is an isolated network of them.
- Low-interaction honeypots (Cowrie, Dionaea, Honeyd) emulate services with limited functionality. They are easy to deploy, hard to compromise meaningfully, and useful for capturing automated scanning, credential-stuffing, and worm-style attacks.
- High-interaction honeypots are real systems with real operating systems and applications, instrumented to capture every action. They produce richer intelligence about attacker tradecraft, at the cost of more careful containment to prevent them from being used as a pivot.
- Honey tokens / honey credentials. Decoy secrets placed in real systems — a "honey" AWS access key in a developer's home directory, a fake admin password in a vault entry, a canary file on a fileshare. Any use of these tokens generates a high-confidence alert. CanaryTokens.org and similar services have made honey tokens extremely cheap to deploy.
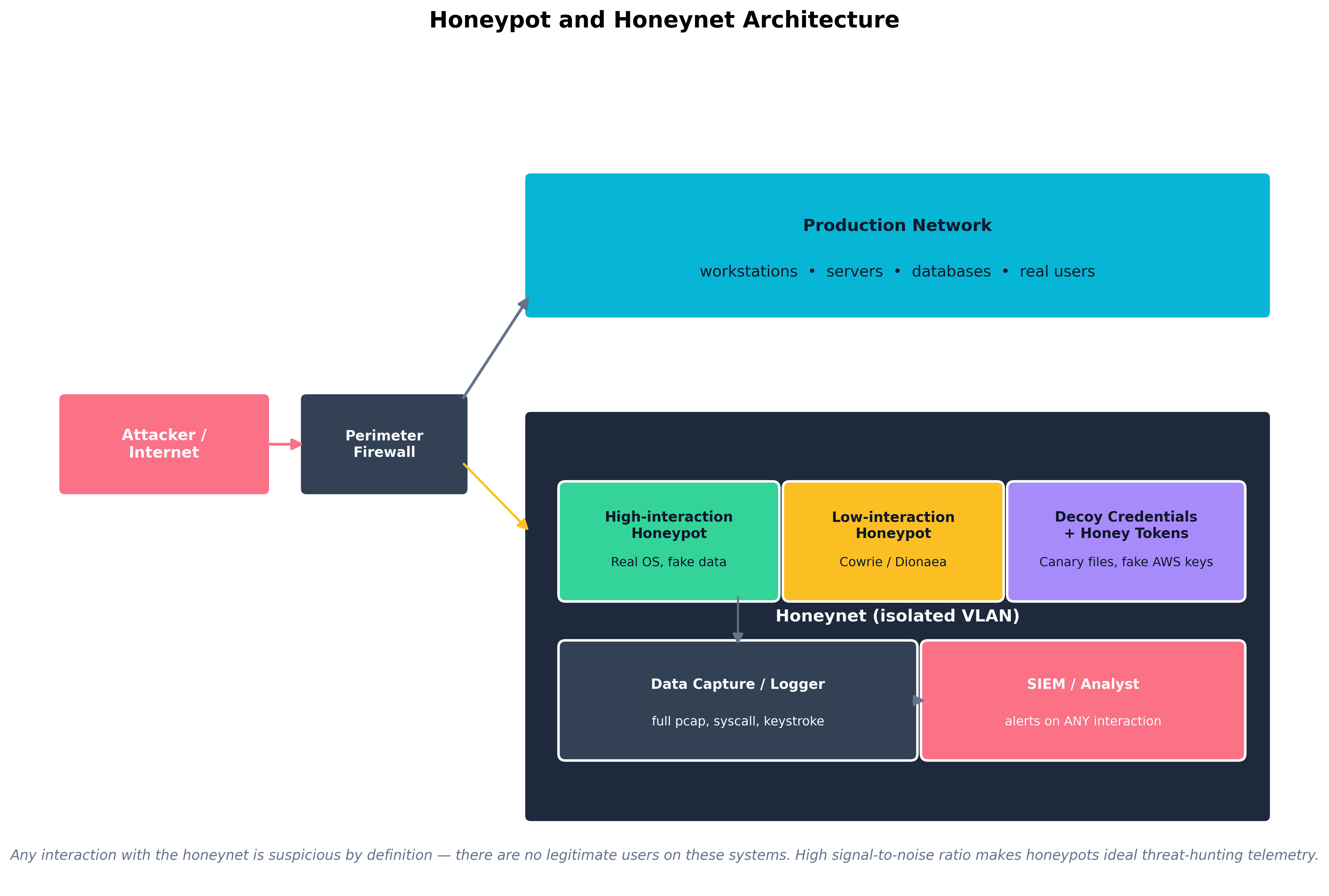 Figure 11.2: A honeynet is an isolated VLAN containing decoy systems and tokens, with every interaction logged and alerted. Because no legitimate users have any reason to touch these systems, the signal-to-noise ratio approaches one — every alert is worth investigating.
Figure 11.2: A honeynet is an isolated VLAN containing decoy systems and tokens, with every interaction logged and alerted. Because no legitimate users have any reason to touch these systems, the signal-to-noise ratio approaches one — every alert is worth investigating.
Hypothesis-Based Searches
A useful hunt is built on a specific, testable hypothesis. Examples:
- Hypothesis: an adversary using BloodHound for AD reconnaissance would issue distinctive LDAP queries. Telemetry: domain controller LDAP query logs. Test: search for LDAP filter patterns characteristic of BloodHound collection.
- Hypothesis: a Cobalt Strike beacon configured with a particular sleep-and-jitter pattern would produce regular outbound HTTPS connections at predictable intervals. Telemetry: netflow + DNS. Test: find hosts whose outbound HTTPS shows strong periodicity over the past 30 days.
- Hypothesis: an attacker performing Kerberoasting would request service tickets for accounts with weak service principal names. Telemetry: Windows Event ID 4769. Test: aggregate 4769 events by requesting account, looking for one account requesting many SPNs in a short window.
- Hypothesis: a malicious browser extension on a developer workstation would exfiltrate clipboard contents to an unfamiliar domain. Telemetry: DNS + EDR network connection. Test: compare developer-workstation DNS query destinations against a known-good baseline.
A hunt that finds something becomes an incident. A hunt that finds nothing becomes a new detection rule that will continue to look for the same pattern automatically — and a documented record of coverage that auditors and leadership can point to.
Case Study
Marriott / Starwood (2014–2018): Four Years of Undetected APT Access
In September 2018, Marriott International disclosed that an unauthorized party had been inside the reservation database of its Starwood subsidiary since 2014 — four years of continuous access before detection. By the time investigators finished counting, the breach involved guest records for approximately 383 million people, including names, mailing addresses, passport numbers (more than five million in unencrypted form), Starwood loyalty account information, and in some cases payment card numbers protected with an AES-128 encryption scheme whose keys may also have been accessible.
The exposure came to light only because Marriott — which acquired Starwood in 2016 — was in the middle of an IT integration project that involved consolidating the reservation databases. As part of that consolidation, the integration team ran a routine scan against the legacy Starwood environment that produced an alert about an unusual encrypted file. Pulling on that thread led investigators to a webshell, the webshell to a longer history of access, and the history of access to a sophisticated and persistent intrusion that had been quietly operating since before Marriott had even started acquisition negotiations.
The detection failures were not exotic. They were the kind of multi-year operational drift this chapter has been describing:
- Monitoring gaps on the legacy environment. Starwood's reservation infrastructure had not been fully integrated with Marriott's SIEM. Telemetry that would have been ordinary for a Marriott-managed system was simply absent from the merged organization's view.
- Long dwell times. Industry estimates at the time placed median dwell time for APTs at roughly 100 days. Starwood's intrusion was fifteen times that. With long enough dwell, any architecture that depends on perimeter prevention and rare audit will fail.
- Failure to surface the intrusion during due diligence. Marriott's 2016 acquisition of Starwood included security due diligence, but did not surface the active intrusion. Subsequent acquisitions across the industry now routinely include compromise assessments performed by external IR firms before close.
- Unencrypted PII. Passport numbers were stored in cleartext for a meaningful subset of records. Modern PCI-equivalent practice would have used tokenization (Chapter 8) so that even a complete database extraction would have yielded surrogate values rather than government identifiers.
The regulatory consequences were substantial. The UK Information Commissioner's Office initially proposed a £99 million GDPR fine; after appeals and adjustments for pandemic-era considerations, the final penalty was £18.4 million. U.S. and other regulatory actions added further costs. Civil litigation continued for years.
Two structural lessons for security operations come from the Marriott / Starwood case:
- Acquired companies are an enormous detection blind spot. Any acquisition large enough to matter is large enough to merit a deliberate, time-boxed program of telemetry integration and compromise assessment before its data is folded into the acquirer's systems.
- Long-dwelling APTs require proactive hunting, not just rules. If a sophisticated adversary stays quiet enough, prevention and traditional detection will not catch them. Hypothesis-based hunts, honey tokens, and behavioral analytics are the controls that close the long-tail gap.
How Do We Leverage Threat Intelligence?
No single organization sees enough of the global threat landscape to build comprehensive defenses on its own observations alone. Threat intelligence is the practice of collecting, refining, and operationalizing information about adversaries — their tools, techniques, infrastructure, and targets — and integrating that information into the SOC's detection and response workflows.
External Feeds, OSINT, and ISACs
Threat intelligence comes from many sources, each with different fidelity and licensing:
- Open-source intelligence (OSINT). Public feeds (AbuseIPDB, AlienVault OTX, abuse.ch's MISP threat feeds, GreyNoise), security blogs, vendor reports, and the daily IoCs that appear in CISA advisories.
- Commercial feeds. Subscription products from Mandiant, Recorded Future, CrowdStrike Falcon Intelligence, Flashpoint, Intel 471, and similar vendors. Generally higher fidelity, with curated context — at substantial cost.
- Government and law-enforcement sources. CISA's automated indicator sharing, FBI / Secret Service notifications, and equivalent national-level alerts.
- Industry ISACs (Information Sharing and Analysis Centers). Sector-specific sharing communities — FS-ISAC for financial services, H-ISAC for healthcare, E-ISAC for electricity, Aviation ISAC, MS-ISAC for state and local governments. Membership-restricted but extremely valuable because the threats are highly relevant.
- Internal intelligence. The most valuable threat intelligence in any environment is generated by that environment's own SOC — IoCs from your incidents, tradecraft from your hunts, infrastructure observed on your honeynet.
- Dark-web monitoring. Services and internal teams that watch underground forums for stolen credentials, mentions of the organization, leaked data, and access-broker listings naming the company.
STIX, TAXII, and Threat Intelligence Platforms
The plumbing that makes all of this manageable is the combination of STIX (the data model) and TAXII (the transport protocol), introduced in Table 11.1. A Threat Intelligence Platform (TIP) — MISP (open source), Anomali, ThreatConnect, ThreatQuotient — sits at the center:
- The TIP pulls STIX bundles from TAXII servers operated by ISACs, vendors, and partners.
- It deduplicates, scores, and ages indicators (an IP that was malicious in 2021 is probably no longer malicious in 2026).
- It pushes high-confidence indicators downstream to enforcement points: firewalls, DNS resolvers, email gateways, EDR.
- It pushes context into the SIEM so that alerts include the matched indicator's known TTPs, campaign, and threat actor.
- It collects observations back from the SOC — every time an indicator matches, that match itself becomes intelligence to share with the community.
| Tier | Audience | Time Horizon | Examples |
|---|---|---|---|
| Strategic | Executives, board | Months to years | Adversary motivations, geopolitical risks, sector-targeting trends |
| Operational | SOC managers, IR leads | Weeks to months | Campaign descriptions, threat-actor TTPs, ATT&CK technique focus |
| Tactical | Analysts, hunters | Days to weeks | Tool families in use, malware variants, evolving tradecraft |
| Technical | Detection engineers, automation | Hours to days | IoCs (IPs, domains, hashes, URLs), YARA rules, Sigma rules |
| Table 11.2: Threat intelligence is layered across audiences and time horizons. The same campaign produces all four tiers of intelligence — strategic for the board, operational for SOC planning, tactical for hunting, technical for blocking. A program that consumes only one tier is incomplete. |
Rule-Based Detection Languages: Sigma, YARA, Snort
Three open detection languages dominate community sharing:
- Sigma. A vendor-neutral SIEM rule format. A Sigma rule describes a detection in YAML, and converter tooling translates it into the underlying query language of whatever SIEM the consumer uses (Splunk SPL, KQL, ES|QL, etc.). The SigmaHQ repository ships thousands of community-contributed rules covering most MITRE ATT&CK techniques.
- YARA. A pattern-matching language for files — used to identify malware families by byte sequences, strings, and structural patterns in executables. YARA rules drive malware sandboxes, EDR scanners, and threat-intelligence platforms.
- Snort / Suricata rules. Network IDS signature languages, widely used and widely shared via Emerging Threats and Talos rule sets.
A well-run detection-engineering program treats these rule libraries the way a software team treats open-source dependencies: pulled in, version-controlled, tested for false-positive impact in staging, and selectively enabled in production.
Warning Threat intelligence feeds are a fast way to introduce both false positives and operational fragility. A blocklist of "known-bad IPs" pulled from a low-fidelity feed and applied to the perimeter without curation will eventually block a legitimate cloud provider IP, a customer's mail server, or your own VPN endpoint. Aging, fidelity scoring, and human review are not optional — they are the difference between an intelligence program and a self-inflicted denial-of-service.
Thought Question Your SOC has just begun consuming a commercial threat-intelligence feed that delivers about 50,000 new indicators per day. Should every one of those indicators flow directly to your perimeter firewall's blocklist? If not, what filtering, scoring, and review process should sit between the feed and the enforcement point — and who in the organization owns the resulting false positives when something legitimate is blocked?
Chapter Review and Conclusion
Security operations is where every other control in this textbook is either validated or exposed. The SIEM pipeline determines what an organization can see; behavioral analytics catch the attacks that prevention missed; threat hunting catches the attackers that detection missed; and threat intelligence ensures that no SOC has to learn every lesson on its own. The discipline that makes all of these work together is engineering rigor applied to detection — schemas, version-controlled rules, measured false-positive rates, hypothesis-driven hunts, and intelligence that is aged and curated, not merely consumed. Hamlet's eleven nights of patient UEBA scoring and Marriott's four years of missed dwell are two sides of the same point: with the right telemetry and the right discipline, even patient adversaries are eventually detectable; without them, the most ordinary intrusion can run for years.
Key Terms Review
- SIEM (Security Information and Event Management): Platform that collects, normalizes, stores, correlates, and alerts on security telemetry from across the environment.
- SIEM Pipeline: Collection → normalization / enrichment → storage / indexing → correlation / detection → alerting / dashboards.
- ECS / OCSF: Elastic Common Schema and Open Cybersecurity Schema Framework — common normalization schemas for security telemetry.
- Hot / Warm / Cold Storage Tiers: Retention tiers from fast and expensive to slow and cheap, balancing query latency with cost.
- Detection-as-Code: Treating detection rules as software — version-controlled, peer-reviewed, tested, and lifecycle-managed.
- Sigma: Vendor-neutral YAML SIEM rule format with converters into specific SIEM query languages.
- YARA: Pattern-matching rule language for identifying malware by file content.
- Snort / Suricata Rules: Open network IDS signature languages widely shared by community and commercial feeds.
- UEBA (User and Entity Behavior Analytics): Behavioral baselining of users and entities to detect statistical anomalies.
- Risk Scoring: Composite numerical score per entity that aggregates anomalies for analyst review.
- Peer-Group Analysis: Comparing a user's behavior against peers in the same role to surface deviations.
- Threat Hunting: Proactive, hypothesis-driven search for adversaries already inside the environment.
- Honeypot / Honeynet: Decoy system / network used to detect and study attacker activity with high signal-to-noise ratio.
- Honey Token / Canary Credential: Decoy secret whose use generates a high-confidence alert.
- Threat Intelligence: Collected and refined information about adversaries — tools, TTPs, infrastructure, and targets.
- OSINT: Open-source intelligence drawn from public feeds, reports, and analyses.
- ISAC: Information Sharing and Analysis Center — sector-specific threat-sharing community (FS-ISAC, H-ISAC, E-ISAC, MS-ISAC, etc.).
- STIX: Structured Threat Information eXpression — JSON data model for threat intelligence.
- TAXII: Trusted Automated eXchange of Indicator Information — HTTPS REST transport for STIX bundles.
- Threat Intelligence Platform (TIP): System that ingests, deduplicates, scores, ages, and operationalizes threat intelligence.
- Strategic / Operational / Tactical / Technical Intelligence: Four-tier layering of threat intelligence by audience and time horizon.
- Indicator of Compromise (IoC): Observable artifact (IP, domain, hash, URL, mutex) associated with malicious activity.
- MTTD / MTTR: Mean Time To Detect / Mean Time To Respond — primary SOC effectiveness metrics.
- Dwell Time: Duration from initial compromise to detection — the canonical measure of detective shortfall.
Review Questions
True / False
- A normalization layer that converts raw logs into a consistent schema such as ECS or OCSF is a nice-to-have optimization but not essential — most modern SIEMs can effectively correlate raw, vendor-specific log formats across different products without a shared schema.
- Hot, warm, and cold storage tiers in a SIEM allow the organization to balance query speed against retention cost, with recent data on fast indexed storage and older data on cheaper object storage for compliance retention.
- The most common failure mode of a SOC is detecting too little — the analyst queue is usually under-loaded with alerts, which is why aggressively turning up rule sensitivity is the correct first response when MTTD is high.
- Sigma is a vendor-neutral YAML rule format that can be converted to the underlying query language of various SIEM products, enabling community sharing of detection logic across different platforms.
- UEBA detects threats by comparing current user and entity behavior against learned baselines, which makes it particularly effective against compromised credentials, insider threats, and post-compromise lateral movement.
- A peer-group analysis comparing a finance analyst's access patterns against other finance analysts can surface anomalous data access that does not violate any explicit access-control rule.
- STIX and TAXII are competing standards for threat-intelligence exchange, so an organization must choose one and avoid the other when integrating with external sharing communities.
- A honey token (canary credential) is a decoy secret placed in a legitimate-looking location whose use generates a high-confidence alert, because there is no legitimate reason for anyone to use it.
- A low-interaction honeypot fully emulates a real operating system and applications, while a high-interaction honeypot simulates only a few services with limited functionality.
- The threat hunt is a hypothesis-driven activity that begins with a specific testable claim about how an adversary would behave and ends either in an incident, a new detection rule, or documented evidence of coverage.
- In the Marriott / Starwood breach disclosed in 2018, attackers had access to the Starwood reservation environment for approximately four years before discovery, and the initial detection came during an IT-integration scan rather than from a SOC alert.
- The four-tier threat intelligence model — strategic, operational, tactical, technical — describes the same intelligence repackaged for different audiences and time horizons, with technical IoCs at the shortest horizon and strategic intelligence at the longest.
- ISACs (Information Sharing and Analysis Centers) are public, anonymous threat-intelligence feeds available to any organization without membership requirements.
- A Threat Intelligence Platform aggregates STIX / TAXII feeds, deduplicates and ages indicators, pushes high-confidence indicators to enforcement points such as firewalls and DNS resolvers, and enriches SIEM alerts with adversary context.
- Applying every IoC from every consumed threat feed directly to the perimeter firewall blocklist is a robust practice because the volume of indicators ensures comprehensive coverage of all current threats.
- Mean Time to Detect (MTTD) and Mean Time to Respond (MTTR) are higher-value executive metrics than "number of events processed," because they measure outcomes the security program is actually trying to improve.
- The highest-leverage single data source in many SOCs is recursive DNS resolver query logs, because most malware resolves a command-and-control domain before initiating any subsequent network behavior.
- YARA rules describe network traffic patterns and are loaded into Snort or Suricata for in-line IDS detection on packet flows.
- In the Hamlet UEBA case study, the off-hours database access alone would have been sufficient to trigger an incident response without any other supporting anomalies, since accessing a database outside business hours always violates security policy.
- A documented, time-boxed compromise assessment of an acquired company's environment before integrating its data into the acquirer's systems is a structural lesson security organizations took away from the Marriott / Starwood breach.
Answer Key
- False. Normalization is the foundation of cross-source correlation. Without a shared schema, joining authentication events from Active Directory with EDR events from CrowdStrike is impractical at scale.
- True. Tiered storage is the standard architectural pattern for balancing query latency, retention cost, and compliance requirements.
- False. The dominant SOC failure is alert overload, not undersupply. Turning up sensitivity without tuning produces noise that hides real attacks.
- True. Sigma's portability across SIEMs is precisely why it has become the lingua franca of community-shared detections.
- True. These are the three classes of threat where the attacker has legitimate access or has otherwise evaded access controls — UEBA's sweet spot.
- True. Peer-group analysis is one of UEBA's most useful primitives precisely because it surfaces deviations from norm without depending on explicit allow / deny rules.
- False. STIX and TAXII are complementary — STIX is the data model and TAXII is the transport. Production deployments use both together.
- True. The signal-to-noise ratio of honey tokens approaches one — any interaction is genuinely suspicious, which is what makes them exceptionally cost-effective detection.
- False. The polarity is reversed: low-interaction honeypots emulate limited services; high-interaction honeypots run real OS and applications with full instrumentation.
- True. This is the canonical structure of a mature hunting program — hypothesis-driven, with all outcomes producing artifacts that strengthen the SOC.
- True. Four years of dwell, discovery during a post-acquisition integration scan rather than via SOC detection — exactly as described in the case study.
- True. The model is one of audience and horizon; the same campaign produces all four tiers of intelligence simultaneously.
- False. ISACs are membership-restricted, sector-specific sharing communities — that membership is what supports the trust required for sensitive sharing.
- True. This is exactly the role of a TIP — the connective tissue between external intelligence sources and internal enforcement and detection.
- False. Unfiltered feed application produces operational fragility (legitimate cloud, partner, and customer IPs eventually get blocked). Aging, fidelity scoring, and human review are essential.
- True. MTTD and MTTR measure detection and response effectiveness — outcome metrics — while "events processed" grows with data volume rather than program quality.
- True. DNS logs are an exceptionally high-leverage telemetry source for malware detection, particularly for C2 callback patterns.
- False. YARA is a file pattern-matching language used by sandboxes, EDR, and IR teams. Network IDS signatures use Snort or Suricata rule formats.
- False. The case-study analysis explicitly emphasized that no individual event would have triggered an incident — it was the composition of anomalies (off-hours access, unfamiliar database, paginating query sizes, personal cloud upload, off-hours-only activity) that made the pattern unmistakable.
- True. Pre-close compromise assessments by external IR firms have become a standard structural response to the dwell-time and integration blind-spot lessons of the Marriott / Starwood breach.